
From Tokenmaxxing to Tokenomics
Why AI productivity should be measured in value per token, not tokens consumed.

In case you haven’t heard the news yet… there’s this buzzword called “tokenmaxxing”. It refers to people and businesses who are burnin’ through as many tokens as possible to prove they’re using the “mostest AI”... <cough> innovation theater <cough>.
The Dumb New Metric
Tokenmaxxing is what happens when companies confuse AI activity with AI productivity. Michael Burry said that tokenmaxxing is a, “crazy, rushed, temporary phase.1” I completely agree.
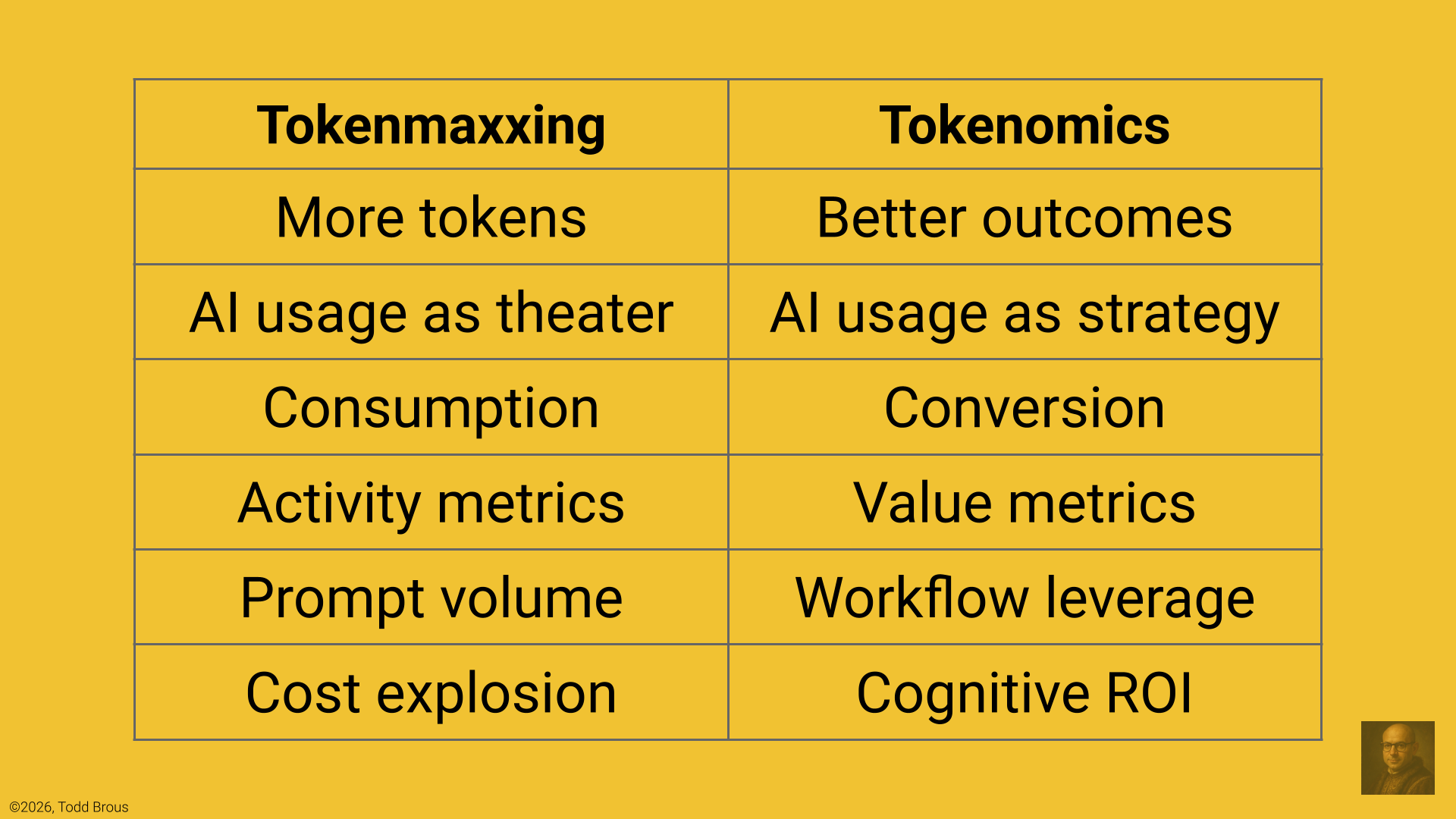
It’s not about using more tokens. It’s about better thinking, better agents, better outcomes.
Businesses are treating tokens like they’re some “proof of innovation”, but tokens are not productivity. They are input costs. The real question is not “How much AI are we using?” It’s “How much value are we creating per unit of AI cognition?”
The Wrong Scorecard
And whenever we try to measure something… we need to be mindful of Goodhart’s Law (“when a measure becomes a target, it ceases to be a good measure”).
“Pretty sure 50% of internal token spend is completely useless, but right now it’s hard to know which 50%.” -Akshat Bubna 2
This sounds like it was inspired by the attributed quote from John Wanamaker, “50 percent of my advertising budget works, I just don’t know which half.”
When token usage becomes the target, the organization doesn’t become more intelligent. It just becomes more expensive.
The Better Metric
Tokenomics is the discipline of maximizing value per token in human-agent workflows.
Tokenmaxxing is what happens when organizations confuse AI activity with AI productivity. Tokenomics is the discipline of converting AI tokens into measurable business value.
Agentic AI Problem
Agentic AI makes this problem worse because agents don’t just answer questions. They plan, search, reason, call tools, retry, reflect, and loop. An inefficient agent is not a chatbot with bad habits. It is a tiny autonomous cost center.
Side rant: Speaking of cost centers and John Wanamaker… the death of bloated advertising budgets will come when brands bypass advertising agencies and finally use data science to figure out which half of their spend actually works. #shapley
And if you want a hint… brands should start looking for the sushi tax.
The brand pays the agency. The agency hires the production, edit, or VFX house. The production house treats the agency producers and creative directors like visiting royalty because, well, that’s how you get the next job. Then all that “relationship-building” gets quietly baked into the bid and passed back to the brand.
So yes... your commercial production budget might include ideation, branding, storyboarding, copywriting, direction, cameras, crews, lighting, editing, VFX, sound, music, and one tiny invisible line item called “somebody else’s 18-course omakase.”
And if you work at a brand... yes, you can build an Agentic AI pipeline that replaces a meaningful chunk of what your agency is charging you for. Maybe not all of it. But enough to make the sushi budget nervous. You just have to be prepared to burn a bunch of tokens.
Now… this is gonna seriously upset a number of my agency and creative friends. They tend to get super sore because they do a lot of the fun, difficult, and important creative work, but they capture almost none of the long-term value.
What they don’t wanna hear is that this is not just a creative problem. It’s a business model problem. The brand takes the business risk. The brand funds the campaign. The brand owns the customer relationship. The brand lives with the upside or the downside.
The agency may help create the value, but it usually does not participate in the risk. And in capitalism, risk is the price of admission to long-term upside.
That’s the uncomfortable truth. Most agencies are not treated like equity partners. They are treated like cost centers. And once brands understand how much of that cost can be measured, automated, or replaced... the sushi tax starts looking a lot less like “relationship-building” and a lot more like margin leakage.
The Efficiency Counter-Signal
At the exact same moment companies are learning how easy it is to waste tokens, researchers are showing us how much efficiency is still trapped inside the system.
Last night during my office hours, I mentioned two important research papers that make AI orders of magnitude more efficient.
DiffusionBlocks
The first is DiffusionBlocks from the freakin’ geniuses at Sakana.ai.3 Their algo potentially democratizes AI training. Right now, training frontier AI models requires thousands of specialized GPUs and tens of millions of dollars, largely because the models are too massive to fit into standard hardware memory. By reducing the training memory by a factor of the number of blocks used, DiffusionBlocks opens the door for individual researchers, students, and smaller startups to train or fine-tune powerful, large-scale AI models on much humbler hardware. Technically, they discovered that data running through a neural network is surprisingly similar to a ‘diffusion model’ (the same algo behind Stable Diffusion, that’s making all the kewl AI images these days.) A diffusion model starts with random noise and gradually clears it up step-by-step until it’s a perfect picture. DiffusionBlocks treats each block of the neural network as one of those “clearing up” steps. Because this is mathematically grounded, the blocks can train independently without losing coordination. BRILLIANT!
OSCAR
The second paper is called OSCAR: Offline Spectral Covariance-Aware Rotation for 2-bit KV Cache Quantization4. (This gets me uncomfortably excited.)
When you chat with an LLM over a long conversation, it stores a history of the interaction in what’s called a Key-Value (KV) cache. This cache grows linearly with the length of the prompt and the number of users, quickly eating up expensive GPU memory and slowing down text generation.
Engineers want to compress this KV cache down to ultra-low precision. Specifically to a 2-bit (INT2), which would theoretically reduce the memory footprint by about 8x compared to standard 16-bit floating point (BF16). However, standard 2-bit compression usually destroys model accuracy because LLM activations contain extreme “outlier” values in certain channels, and this compression loses those outliers.
OSCAR’s big leap is shifting the goalpost from raw data reconstruction to downstream attention impact. Instead of trying to perfectly preserve the exact original numbers in the cache, OSCAR asks: “What does the model’s attention mechanism actually care about?” It runs a lightweight, one-time calibration pass to calculate how the model focuses its downstream attention, and it basically finds the mathematical directions that the model reads most strongly.
By aligning the BF16 to INT2 compression with the model’s actual mathematical intent, OSCAR achieves staggering system gains without losing the model’s mind. They maintain a 1.4-point gap with the uncompressed performance. (That’s insanely close!) And this cuts the KV cache memory usage by 8x.
Signals Decoded
The next phase of AI will not be about who uses the most tokens. It will be about who creates the most value per token.
What this means is that we’re seeing MASSIVE algorithmic gains, at the same time we’re seeing increased demand for tokens, at the same time we’re seeing massive investment in AI data centers.
And we’re moving towards an “unlimited intelligence” stage where edge devices (like laptops and smartphones) will run the equivalent of SOTA models that require cloud compute.
I think we’re gonna see an inflection point in late 2027 or early 2028.
Not because companies learned how to use more AI.
Because they learned how to waste less of it.
The next phase of AI will not be measured in tokens consumed. It will be measured in value created.
Tokenmaxxing is AI theater. Tokenomics is AI strategy.
https://www.businessinsider.com/big-short-michael-burry-nvidia-stock-price-crash-ai-tokenmaxxing-2026-5
https://www.businessinsider.com/ai-spending-roi-concerns-tokenmaxxing-uber-coo-andrew-macdonald-reaction-2026-5
https://pub.sakana.ai/diffusionblocks
https://arxiv.org/abs/2605.17757