


DeepResearch Bench: which 'deep research' tool is the best?
The race to Research Supremacy now has comparison benchmark!

According to this paper, the current winner is Gemini-2.5-Pro (preview).
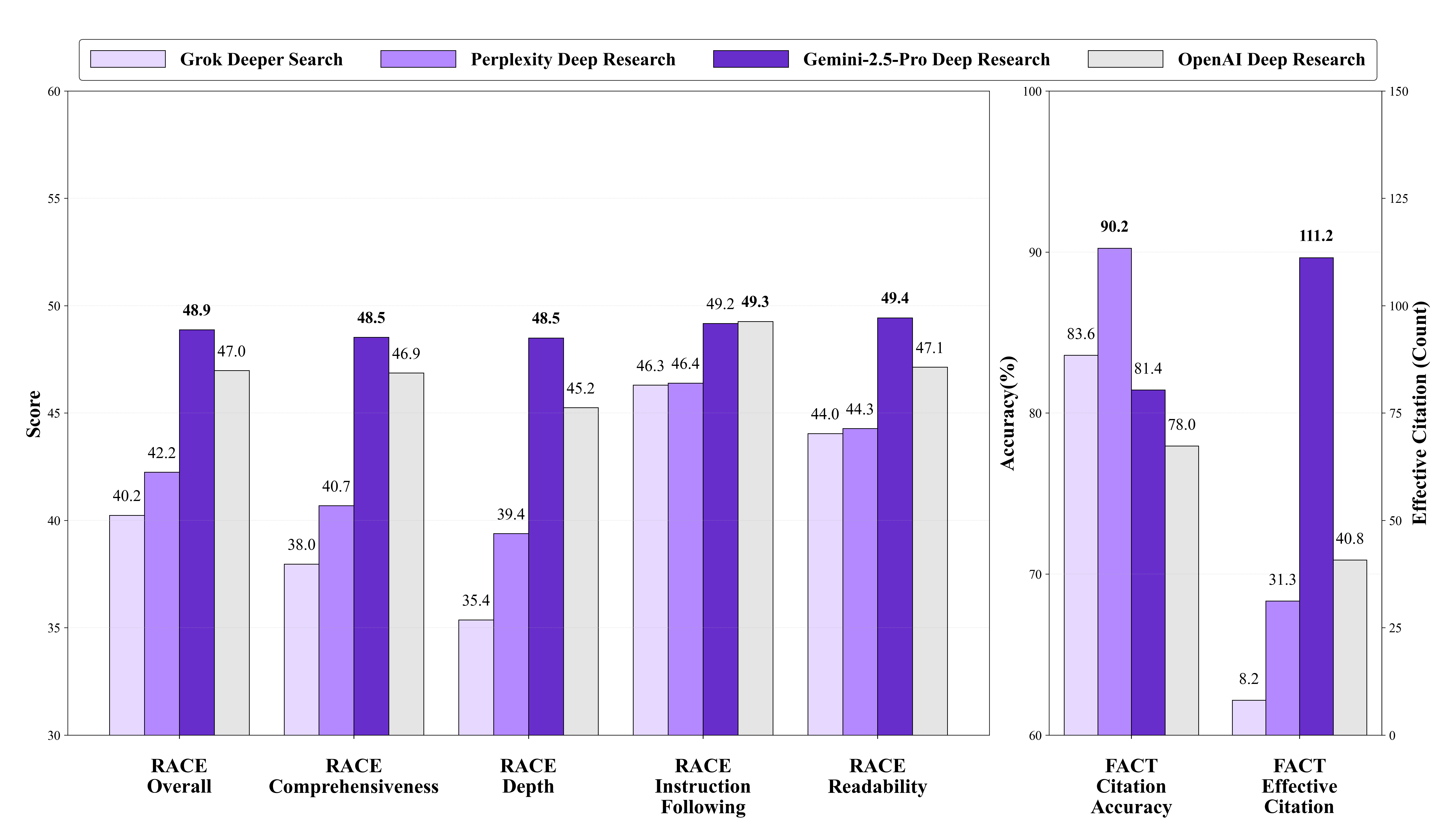
They also have a Leaderboard on Huggingface where you can compare the individual results from each tool, so I imagine this will get updated over time.
Ok… what is “DeepResearch Bench”? Well… it’s, “benchmark consisting of 100 PhD-level research tasks, each meticulously crafted by domain experts across 22 distinct fields.” So, the folks who helped put this together are much smarter than I am.
Here’s how they built it:
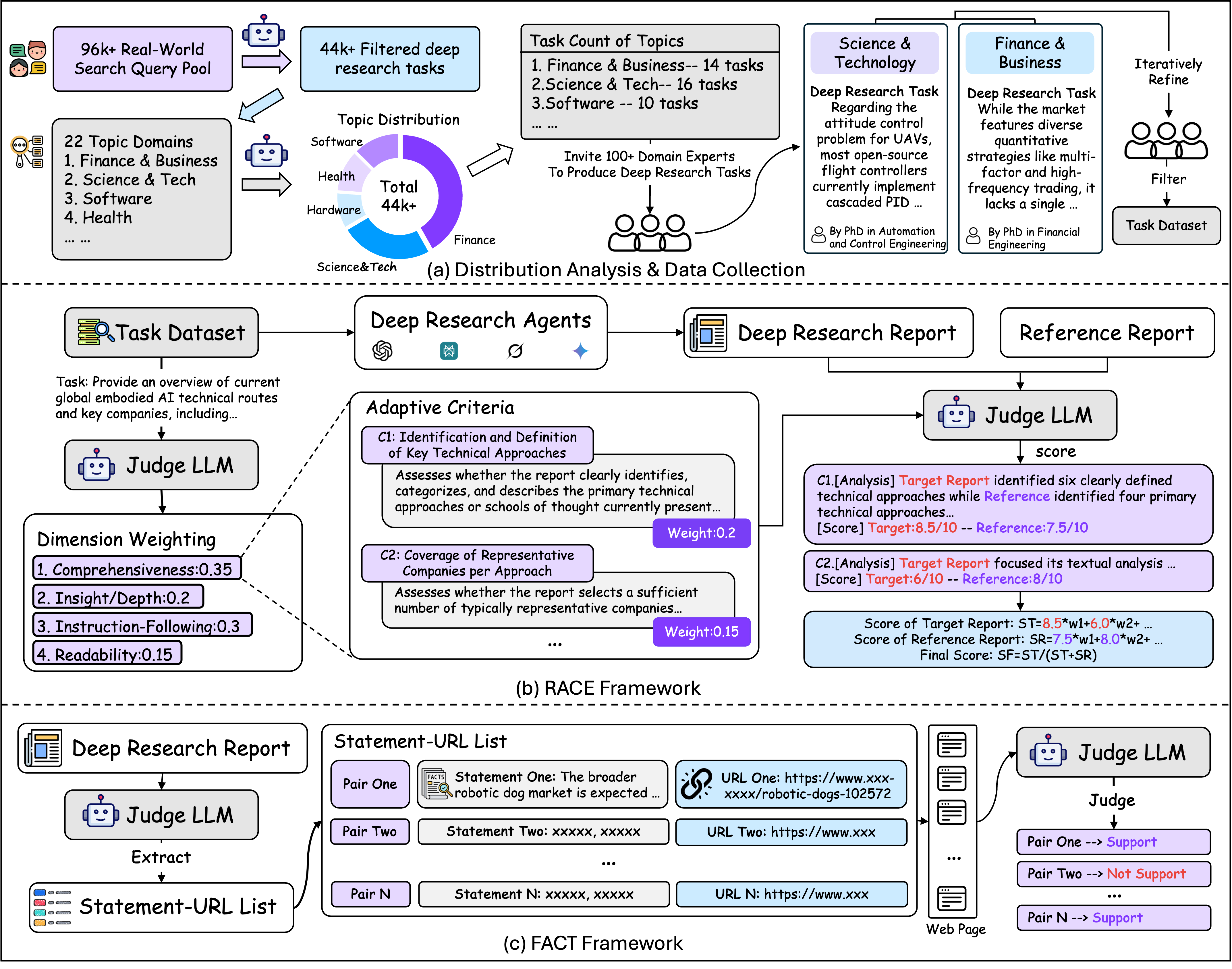
Since that’s a lot to follow… here’s a brief breakdown of their workflow:
Create tasks: 100 PhD-level prompts
Agent Execution: Dispatch a Deep Research Agent to complete the task.
Evaluate the output:
Compare against an expert reference report for quality.
Count and verify the citations.
Score the results
And if you’re paying attention they have not one, but two frameworks in there: RACE and FACT.
RACE: assesses the overall quality of the report and how well the report satisfies the task in a way that is aligned with how humans would judge it’s academic quality.
FACT: measures the effectiveness of the report’s citations. (Because everyone hates citation hallucinations!)
Now, if you’re building an Agentic Deep Research tool of any type… I highly suggest taking a look at their prompts! They’re in their github repo and in the appendix of their paper.